
Ve finálním díle série se podíváme na metodu fingerprintingu neboli metodu otisků. Nepracuje s otisky prstů, ale s otisky bezdrátových sítí v budově. A díky tomu nám určí lokaci s přesností na konkrétní místnost v budově. Mrkněte, jak na to!
Lokalizace s přesností na místnost snadno a rychle (4/4)

Přes Dead Reckoning a Multilateraci jsme se dostali k další metodě. Poslední metodě, kterou bych vám rád představil. I tato používá zase úplně odlišný přístup než metody předchozí. Jmenuje se Fingerprinting method, neboli metoda otisků.
Otisky … prstů?
Otisky, to nezní zrovna jako způsob zjištění polohy v budově. Tahat s sebou otisk patra ve smyslu modelu budovy by bylo nejen nepraktické, ale často i nereálné. Tato metoda naštěstí není o tom, jak nejlépe udělat otisk patra. Je o otisku místa.
Když se podíváte po chodbách v různých budovách, tak jsou často stejné. Moc se nemění. Nemůžeme říct o nějakém konkrétním místě na chodbě, že má nějaký otisk (ve smyslu modelu) a že v celé budově není žádné podobné místo. Jenže ono je opravdu jedinečné, jenom to nevidíme. V budovách je určitě k dispozici místní WiFi, která může ale nemusí mít stejný název z různých přístupových bodů.
Vraťme se k příkladu chodby. Pokud je chodba dlouhá, tak je logicky na její pokrytí potřeba více přístupových bodů. Tedy i když chodba na první pohled vypadá stejně, můžeme ji rozdělit na části, které jsou pokryté signálem z různých přístupových bodů. Pokud to takto aplikujeme na celou budovu s mnoha přístupovými body, dojdeme k závěru, že můžeme každé místo v budově zcela jasně identifikovat podle jeho otisku bezdrátových sítí, tak jako člověka podle jeho otisku prstů.
Otisk místa
Co je to otisk místa? Jak jsem psal, v rámci tohoto článku to bude otisk bezdrátových sítí, pouze seznam přijímaných signálů z různých přístupových bodů a jejich sil. Nic jiného.
No jo, namítnete, ale přece máme otisk míst různě po budově. Co s tím? Co se stane, když uživatel bude chtít najít svou pozici v budově? Předně je potřeba mít databázi posbíraných otisků někde dostupnou. Teď je jedno, jestli to je někde na serveru, nebo v telefonu uživatele.
A jak nejjednodušeji najít nejvhodnější otisky? Tak, že jeden vytvoříme.
Takže pokud máme databázi otisků z různých míst po budově, svou pozici nejlépe najdeme tak, že si vytvoříme další aktuální otisk a ten porovnáme s již existujícími. V ideálním případě nám stačí najít ten nejbližší/nejpodobnější. Jak je ale porovnat? S tím nám pomůže krása matematiky.
Mnoharozměrné peklo
Teď přichází asi nejtěžší část z celé série; způsob, jakým otisky porovnávat. Ve zkratce je to vlastně velice jednoduché; porovnávám velikost vektorů. Jenže ten vektor má tolik rozměrů, kolik je v budově přístupových bodů.
Pokud je tedy tato metoda aplikována na budovu s několika desítkami přístupových bodů, tak se nám z toho na první pohled stává nepředstavitelný mnoharozměrný mišmaš. Tak hrozné to ale není, protože stejně jako u většiny věcí v informatice, i u téhle můžeme najít podobnost v běžném životě.
Jako příklad si vezmu skříň, respektive několik různě velkých skříní. Jsou to jednoduché objekty, které mají nějaké rozměry. To jsou hodnoty velikosti ve třech rozměrech: x, y a z. Délka, šířka a výška.
Každou skříň můžeme definovat bodem v kartézském prostoru, který definuje její velikost vzhledem k počátku. Když roh skříně posadíme do počátku, tak se tento bod nachází v protilehlém rohu daném prostorovou úhlopříčkou, která prochází počátkem. Tedy je to ten nejvzdálenější bod skříně od počátku. Ilustrační obrázek je jako obvykle dvourozměrný, ale princip je nezávislý na počtu rozměrů.
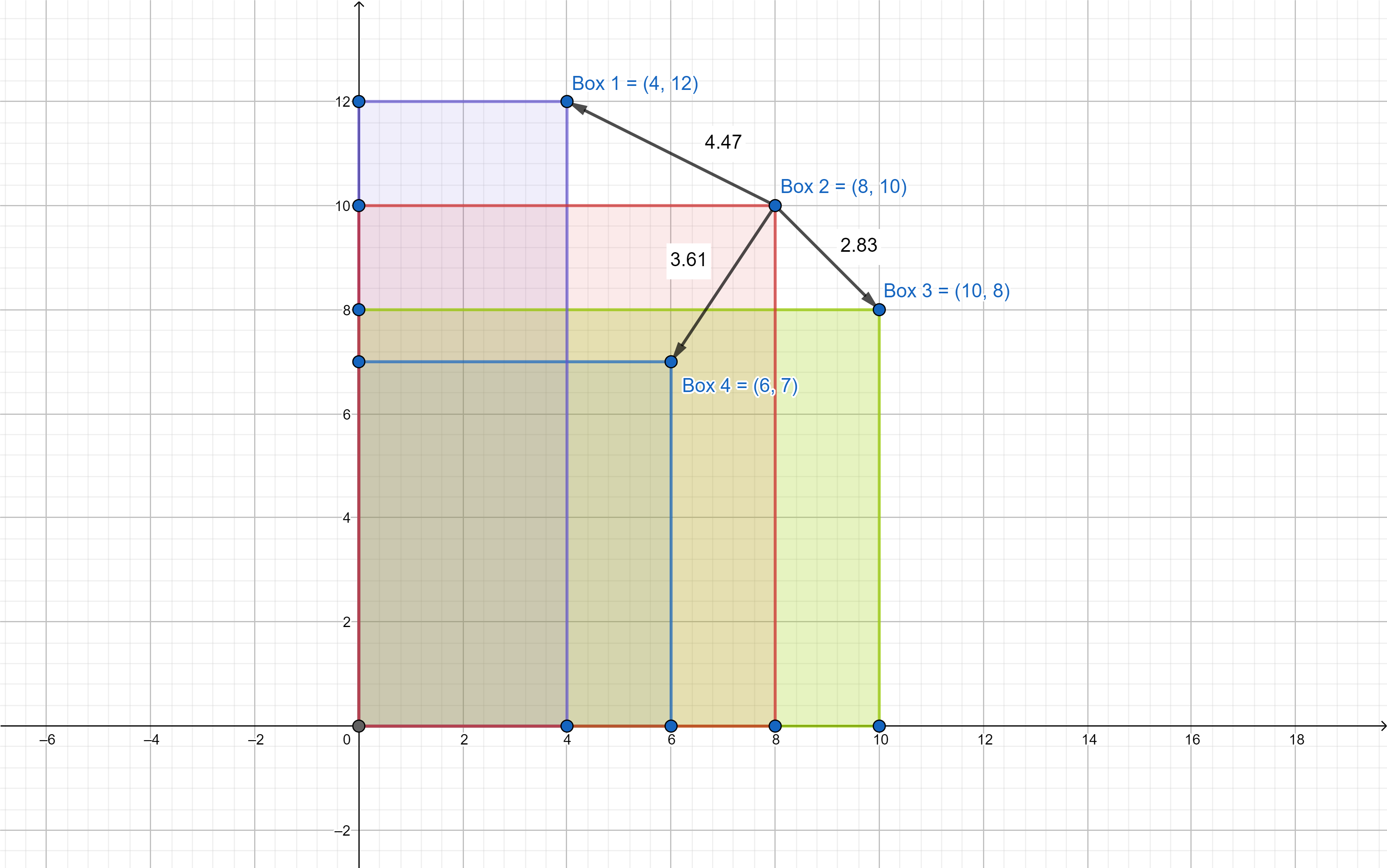
No a jak porovnáme, které jsou si velikostně nejpodobnější? Mohli bychom zvolit třeba objem. To je dobré hodnotící kritérium. Jeho problém ale je, že velmi vysoké skříni bude nejpodobnější velmi široká skříň. To asi není správně, že? Proto je nejlépe popisující prvek každé skříně právě ten bod. Tím bodem totiž jasně definujeme, jak skříň velikostně vypadá.
A jak je tedy porovnat? Máme jednu skříň a tu musíme porovnat se všemi ostatními. Máme jeden bod a musíme jej porovnat s ostatními. Neboli máme najít nejbližší bod od toho určeného. Analytická geometrie nám v tom elegantně pomůže. Vytvoříme si vektory, kde máme jeden bod pevně daný (ten zadaný; skříň, vůči které porovnáváme) a druhý bod budou jednotlivé zbylé body (alias zbylé skříně). Kdybychom to kreslili na papír (viz obrázek), měli bychom teď hromadu čar. Bylo by i pěkně vidět, které vektory jsou kratší a které delší. Bohužel, počítač nevidí nic tak jasně jako my. Proto to musíme přeložit do řeči čísel.
Když už máme vektor, co se s ním dá dělat? Vypočítat velikost. A když máme velikost, můžeme je vzájemně porovnat. A voilá, vektor s nejkratší vzdáleností nám najde tu nejpodobnější skříň!
A úplně stejně najdeme i nejbližší místo z databáze otisků. Jen našimi rozměry nebudou rozměry budovy, ale přijímané hodnoty z různých vysílačů. Vůbec nevadí, že ze všech přijímačů nepřijímám signál, i to je podstatná informace. Jak je budeme porovnávat? Vytvoříme si vektor a spočítáme jeho velikost. Existuje ale vůbec nějaký vzorec pro výpočet velikosti takového vektoru? Když si ho složíme, tak určitě… Já mám oblíbený tenhle:

Vypadá složitě, suma, nějaká mocnina, … Ale je vlastně jednoduchý. Říká jen: “Vypočítej odchylky v jednotlivých rozměrech. Ty umocni, sečti a celé to odmocni.” Je to euklidovská vzdálenost neboli matematicky euklidovská metrika. Já ji mám rád pro jeden její speciální případ: její dvourozměrná verze se nazývá Pythagorova věta. Krásné, ne?
A s vypočítanou velikostí pak už můžeme jednoduše najít nejbližší místo. Ale jako v předchozích dílech, i tato metoda má své mouchy.
Ideály matematiky zpátky k realitě
Jak už jsem psal v předchozím odstavci, potřebujeme databázi otisků. Způsoby, jak vytvořit takovou databázi, by byly na další sérii, nicméně nám zatím bude stačit ten základ. Předně je potřeba jich mít co nejvíc od různých zařízení.
Každý telefon přijímá signály zcela jinak. Proto je dobré si do otisku uložit i typ telefonu a jeho pozici v prostoru, protože i to může hrát důležitou roli. Ty otisky je také dobré nasbírat v průběhu času několikrát. Třeba ráno, v poledne a večer. Když jsem totiž tuhle metodu programoval, stalo se mi, že vysílače v budově si samy upravovaly vysílaný výkon podle poptávky. Večer tady stačilo budovu obsloužit čtyřmi vysílači, zatímco odpoledne jich bylo potřeba šestkrát tolik.
Jak hustě je potřeba vytvořit otisky do databáze? Empiricky se mi osvědčily každé dva metry. Stačí jen orientačně. Tahle metoda je dost robustní.
Když ale vytvoříme tolik otisků… To bude docela nápor na výpočetní výkon, že? Může i nemusí. Pokud budu porovnávat se všemi otisky, kterých může být třeba miliony, tak to bude nápor. Pokud je profiltrujeme, například podle přijímaných MAC adres přístupových bodů, můžeme mít z pár milionů otisků jen pár tisíc. Pokud navíc přidáme časovou filtraci, třeba rozsah dvou hodin, můžeme se dostat na stovky otisků. A to už takový nápor není.
Tuhle metodu nezradí ani výměna přístupového bodu. Pokud se tak totiž stane, moc to samotný výpočet neovlivní. Všechny otisky totiž budou mít připočtenou stejnou odchylku, která v porovnávání nemá žádný vliv. Z toho ale vychází jedna důležitá věc – je nutné databázi průběžně aktualizovat.
Přesnost na místnost
Přesnost, alfa a omega každé z těchto metod. Jak napovídá název i popis celé téhle série, tato metoda má přesnost tak šest až sedm metrů ve volném prostoru. Typicky v dlouhých chodbách a podobných místnostech. Není tak dobrá, aby vám řekla, kde v místnosti uživatel je. Ale je dostatečně dobrá na to, aby vám řekla, ve které místnosti se nachází. A to je často dostatečné řešení.
Závěr
A to je vše. Snad se mi během této série podařilo osvětlit principy a přístupy k tak zajímavému tématu. Jde krásně vidět, jak jsou zmíněné přístupy daleko od ideálu, nicméně společně by mohly vytvořit hodně zajímavý produkt 😉
Možná vás zajímá, jak jsem se k tomu zapeklitému tématu dostal. Může za to škola, respektive má bakalářská práce. Díky ní jsem musel celou problematiku nastudovat, až to nakonec vyvrcholilo v napsání aplikace určující polohu pomocí fingerprintigu pro smartphone se systémem Android. Pak jsem o tom tématu už v rámci firmy přednášel, a nakonec jsem napsal tuto sérii. A toho si v eManu moc vážím – i když jsi nováček, klidně ti dovolí reprezentovat firmu a psát na blog. Ať jsi čerstvě po škole nebo senior s mnohaletými zkušenostmi. Důležité je, že máš co říct.